Import and update data
Overview
Administrators can easily import data into Skedulo from anywhere that supports CSV files.
Import data
Create an import task
To import your data, you must first create an import task.
To create an import task:
- On the Data import/export page, click Create Task.
- From the task menu, select Import. The Import wizard opens on the Task details page.
Task details
Fill in the task details to specify whether you want to insert new or update existing records, and to specify into which object you want to import the records.
- Select an Operation Type. You can choose to create new records or update existing records.
- Insert — Select this option to create new records.
- Update — Select this option to update existing records.
- From the Object dropdown list, select the object into which you wish to import the data.
- Click Browse and locate the CSV file you want to import.
- Click Continue.
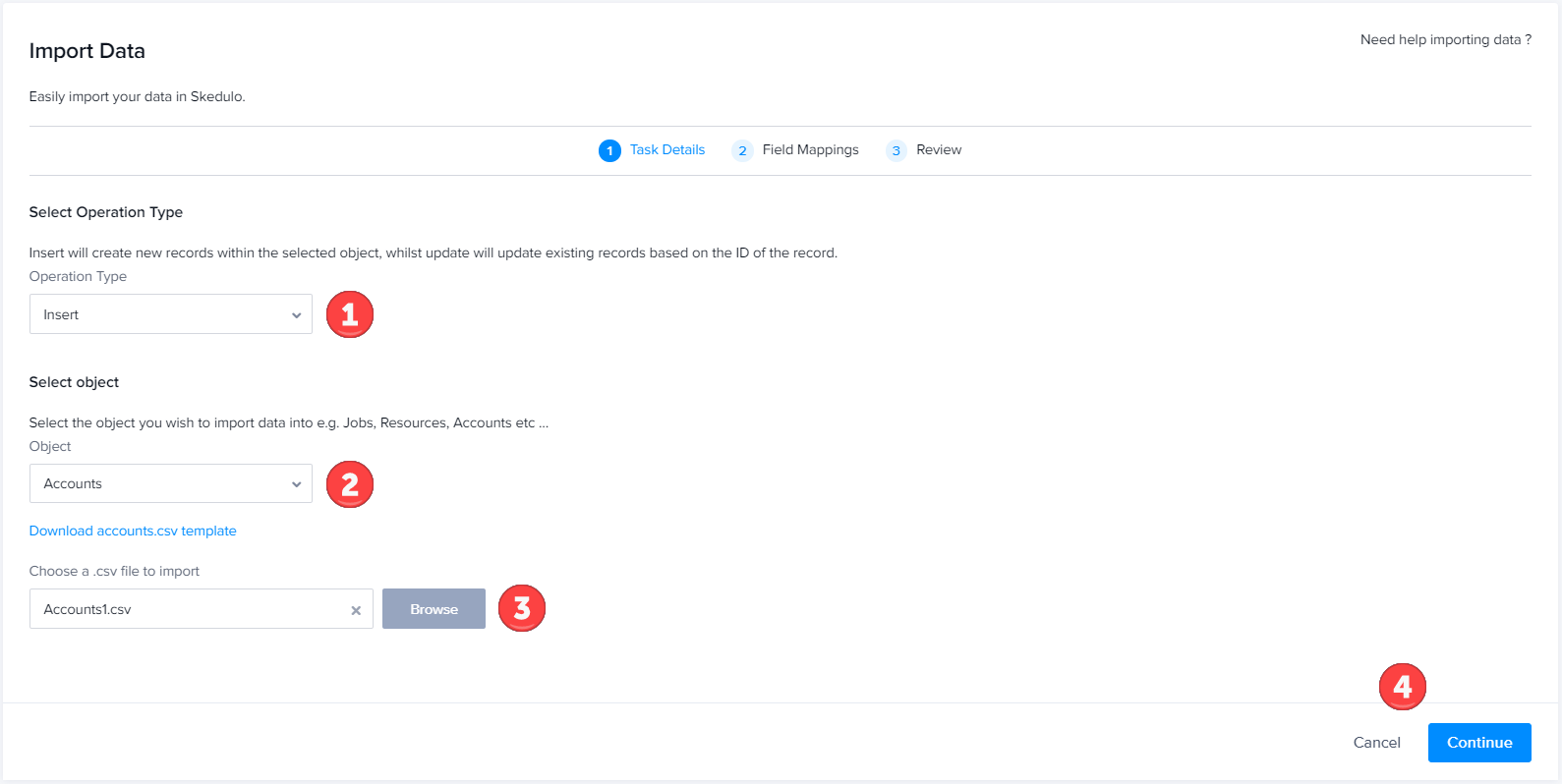
Field mappings
Map your CSV columns to your Skedulo fields. Fields are ordered based on the columns in the CSV file, and any fields that match existing Skedulo fields will map automatically.
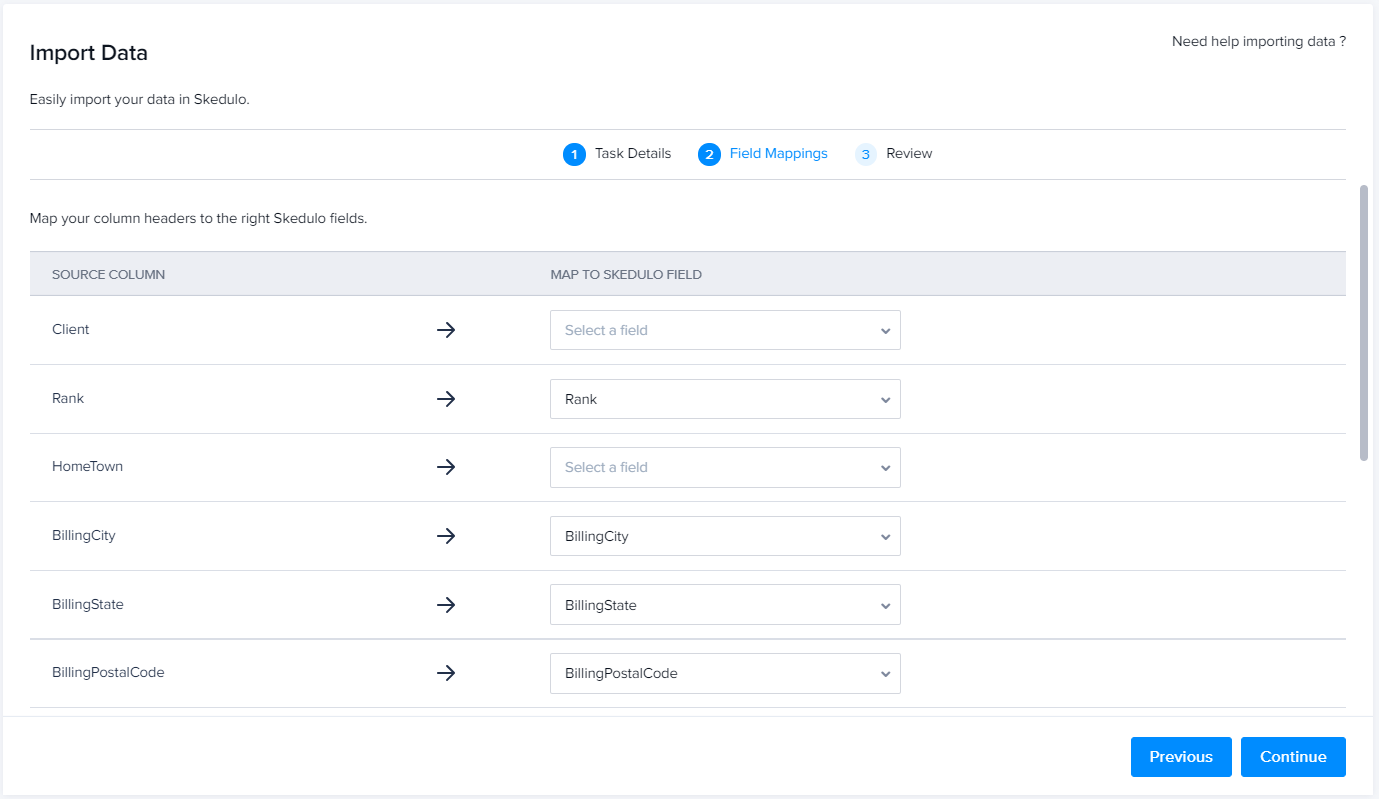
Use the quick find at the top of the selection dropdown to search through your Skedulo fields.
Note
For Date field formats: If you have used only one character for values below 10 for the day or month (for example 5/3/2018 rather than 05/03/2018), you can select the format DD/MM/YYYY or MM/DD/YYYY, as required, without adding the leading zero.Review
The final step is the Review page, which provides a brief summary of the task details.
If required, you can specify the date and time formats and time zone that is used in the data you are importing. This will ensure that the data is correctly converted when it is imported. See the timezone field section below for more information about the impact these fields can have on your data.
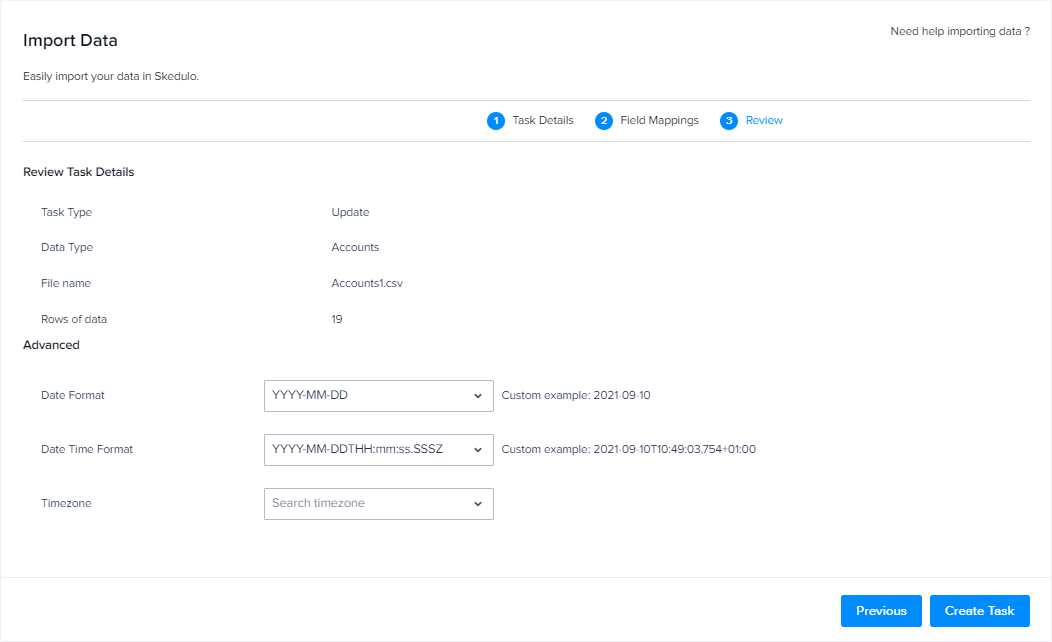
Click Create task to save your task and run it immediately.
Understand the timezone field
The Advanced fields in the Review page are important for two parts of the importing process:
-
For the data loader to understand the date and time fields in your file: If the Date-time format field is not set to the default (UTC) and a timezone is selected, then the data loader will use the information in these fields to understand the date and time data in your file, which it needs for the next step.
-
Converting the date and time data: When the data is imported into Skedulo, it is converted from the timezone specified to match the timezone of the jobs and resources in the system.
Note
The values selected in the Date-time format and Timezone fields can change the values of the dates and times in your data. Be sure to select the correct values for the format and timezone that your data is in when loading a file.The following examples demonstrate how the Date-time format and Timezone fields impact the data being imported:
Scenario 1
| Date-time format field value | YYYY-MM-DDTHH:mm:ss.SSSZ This is UTC, which is the default value. The Z indicates that UTC is used in the CSV file being imported. |
| Timezone field value | N/A Any Timezone field selection will not be taken into account because the Date-time format field already indicates UTC is in use. |
| Time in CSV file |
|
| Time in Skedulo after import |
|
| Explanation | The value imported will depend on the work’s region. Because we are using UTC in the CSV file, the time after converting is unchanged. When the data is imported, the data loader takes the work’s region into account. Therefore, in this example, the system is converting UTC’s 10AM to Berlin or Ho Chi Minh’s equivalent local time. |
Scenario 2
| Date-time format field vale | MM-DD-YYYY HH:mm:ss (Or any format other than YYYY-MM-DDTHH:mm:ss.SSSZ) |
| Timezone field value | Europe/London (UTC+1) |
| Time in CSV file |
|
| Time in Skedulo after import |
|
| Explanation | Because Europe/London was selected as the timezone in the CSV file, the data loader will convert London’s 10AM to the corresponding time in Berlin or Ho Chi Minh. |
Update data
When updating data, you must provide the Skedulo record UID(s) you wish to update.
There are two ways to locate the ID of a Skedulo record:
- Run an export operation to retrieve object data (records). Each row in the export will contain a “UID” column which is the record ID.
- Use GraphQL to query the object and return the UID in the response. To learn more about GraphQL queries, please see GraphQL queries.
Task statuses
| Status | Description |
|---|---|
| Processing | The task is running (importing or exporting data). |
| Completed | The task has finished running and all the records are processed (with or without errors). |
| Canceled | The task has stopped for one of the following reasons: an administrator canceled the process; there has been a connectivity failure; or an unexpected issue has caused the task to stop. |
Feedback
Was this page helpful?